BLOG
Dal MMM statico al MMM che impara: il ruolo del GeoLift
Come gli esperimenti geografici alimentano un loop di calibrazione continua che rende il Marketing Mix Modeling sempre più preciso nel tempo.
Il Marketing Mix Modeling è oggi lo strumento più solido a disposizione di un CMO per capire cosa genera vendite. Ricostruisce, partendo da serie storiche di spesa media, vendite e covariate esterne, il contributo di ogni canale al business. È robusto al signal loss, indipendente dai cookie, scala su anni di dati e produce ROAS, curve di saturazione e raccomandazioni di allocazione che alimentano decisioni da decine – o centinaia – di milioni di euro.
Ma c’è una caratteristica del MMM che spesso viene fraintesa: un buon MMM non è un report. È un sistema vivo.
Un modello consegnato e archiviato perde valore col tempo. Un modello che apprende, che si calibra contro evidenze nuove, che integra ogni trimestre informazioni causali fresche, diventa progressivamente più preciso – e produce decisioni progressivamente più audaci, perché la fiducia nei numeri cresce.
Il GeoLift è il meccanismo che rende possibile questo apprendimento.
Cosa fa il GeoLift, in due paragrafi
Il GeoLift è una metodologia di esperimento incrementale basata su un’idea semplice: dividere le aree geografiche del mercato in gruppi di trattamento e controllo, ed eseguire un test controllato che isola l’effetto causale di un canale o di una campagna.
Tecnicamente sfrutta il synthetic control method: invece di confrontare ingenuamente le aree esposte con quelle non esposte, costruisce un “controllo sintetico” come combinazione pesata di aree di controllo che replichi fedelmente l’andamento pre-test del gruppo trattato. La differenza tra l’osservato e il sintetico, durante il periodo di trattamento, è l’effetto causale incrementale – con tanto di intervallo di confidenza.
Il risultato è una misura causale, non correlazionale, di quanto un canale generi vendite incrementali in un dato contesto.
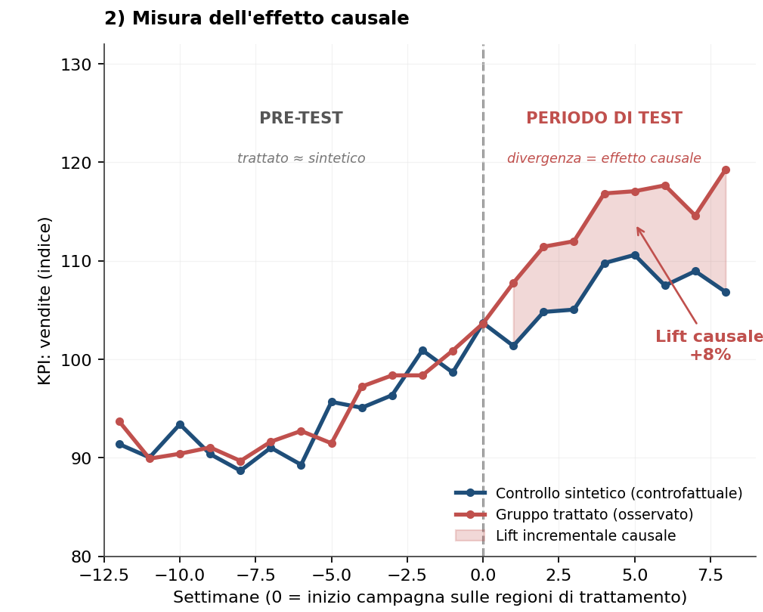
F: durante il pre-test il gruppo trattato e il controllo sintetico hanno andamenti sovrapponibili; quando parte la campagna, la divergenza tra le due curve è il lift causale incrementale.
Il loop di miglioramento continuo
Qui sta il punto centrale di questo articolo. Il GeoLift, da solo, è un esperimento puntuale. Il MMM, da solo, è un modello che copre tutto il media mix in continuo. Insieme, in un’architettura ben disegnata, formano un ciclo di apprendimento causale che si autorinforza.
Funziona così:
- Il MMM produce le sue stime – ROAS, saturazioni, contributi per canale – basate su mesi o anni di osservazioni storiche. È il backbone strategico, sempre attivo, sempre aggiornato.
- Il GeoLift testa, periodicamente, i punti più strategici. Non tutti i canali, non tutto il tempo: i canali dove le decisioni di allocazione sono più impattanti, o dove l’incertezza del modello è più alta, o dove c’è dibattito interno sull’efficacia.
- Il risultato del GeoLift entra nel MMM come prior informativa. Nei modelli bayesiani – che sono lo standard del MMM moderno – un esperimento causale non è un “controllo esterno”, ma un’evidenza che vincola direttamente le distribuzioni a posteriori dei coefficienti. Il MMM impara.
- Il ciclo riparte. Il MMM aggiornato suggerisce nuove allocazioni, nuovi canali da testare, nuove ipotesi da validare. Ogni trimestre il sistema sa qualcosa di più, con meno incertezza.
L’effetto cumulativo è importante: dopo due o tre cicli, gli intervalli di confidenza si stringono, le raccomandazioni diventano più decisive, e il marketing team può permettersi scelte di allocazione che con un modello “fermo” non avrebbe mai osato.
I prerequisiti per fare un GeoLift serio
Prima di entrare nel test design, è onesto chiarire quando un GeoLift è effettivamente eseguibile. Sono prerequisiti tecnici e operativi che, se mancano, fanno fallire silenziosamente il test – o peggio, producono risultati apparentemente significativi ma inaffidabili.
- Target KPI disponibile a livello regionale. Vendite, conversioni, traffico store o qualunque outcome che sia il vero target del media. Frequenza minima settimanale (idealmente giornaliera): un KPI disponibile solo a livello mensile riduce drasticamente la potenza statistica.
- Capacità tecnica di differenziare il budget per regione sulle piattaforme media coinvolte. Banale per Meta e Google, meno banale per CTV, programmatic con DSP eterogenei, o radio locale.
- Storico pre-test sufficiente. Il synthetic control ha bisogno di costruire la sua “controfattuale” partendo dal passato: idealmente almeno 6 mesi di dati regionali, mai meno di 12 settimane.
- Variabilità geografica del KPI. Se il fatturato è ultra-concentrato (es. 80% Lombardia), non c’è abbastanza “massa” sulle altre regioni per costruire un controllo sintetico solido. È un caso che si verifica in alcuni e-commerce molto verticali.
- Pulizia del contesto sperimentale. Durante il test, gli altri canali e le altre attività commerciali devono restare il più possibile costanti tra trattamento e controllo. Una promo nazionale che parte a metà test, un lancio prodotto che varia per regione, una variazione di pricing — tutto questo contamina il segnale.
- Ciclo di acquisto compatibile con la durata. Se il prodotto ha lead time di conversione di 2-3 mesi (B2B, automotive, alcuni settori finance), un test di 6 settimane vede solo la coda iniziale dell’effetto. Esistono design alternativi per questi casi, ma richiedono altra preparazione.
Questi sei punti vanno verificati prima di iniziare a disegnare il test. Saltarli è la prima causa di GeoLift inconcludenti.
Come si progetta un GeoLift: la "coperta corta" del test design
Una volta verificati i prerequisiti, il test design è un esercizio di equilibrio tra tre vincoli che si tirano l’un l’altro: scelta delle regioni, durata, budget e errore statistico ammesso. Cambiarne uno costringe a rivedere gli altri – è una coperta corta, e va negoziata in modo trasparente con il business.
Scegliere le regioni: il trade-off strategico
La selezione delle regioni è la decisione più sottovalutata, e quella che più spesso compromette i test. Non è solo una questione statistica: è anche una scelta strategica.
Sul piano statistico, le regioni di trattamento e controllo devono essere molto correlate tra loro nel pre-test. Se la regione X e la regione Y si muovono storicamente insieme – stessi pattern stagionali, stesse risposte a shock esterni — allora il controllo sintetico costruito a partire da Y sarà un buon proxy di “cosa sarebbe successo a X senza il trattamento”. Se invece le due regioni divergono in modo erratico, il controllo sintetico è rumoroso e il test perde potenza.
Sul piano strategico, c’è un secondo vincolo: le regioni di trattamento devono essere rappresentative del country, ma non così strategiche da rendere il test commercialmente insostenibile. Se voglio testare lo spegnimento di un canale (per misurarne l’incrementalità reale), spegnerlo in Lombardia significa rinunciare a una quota enorme di vendite. Meglio scegliere regioni medio-piccole, ben correlate con il country, dove il costo opportunità del test sia accettabile. Viceversa, per un test di aumento del budget, regioni piccole permettono di raddoppiare o triplicare la spesa locale senza far esplodere i costi assoluti – ma se la regione è troppo piccola, il segnale incrementale rischia di non essere rilevabile.
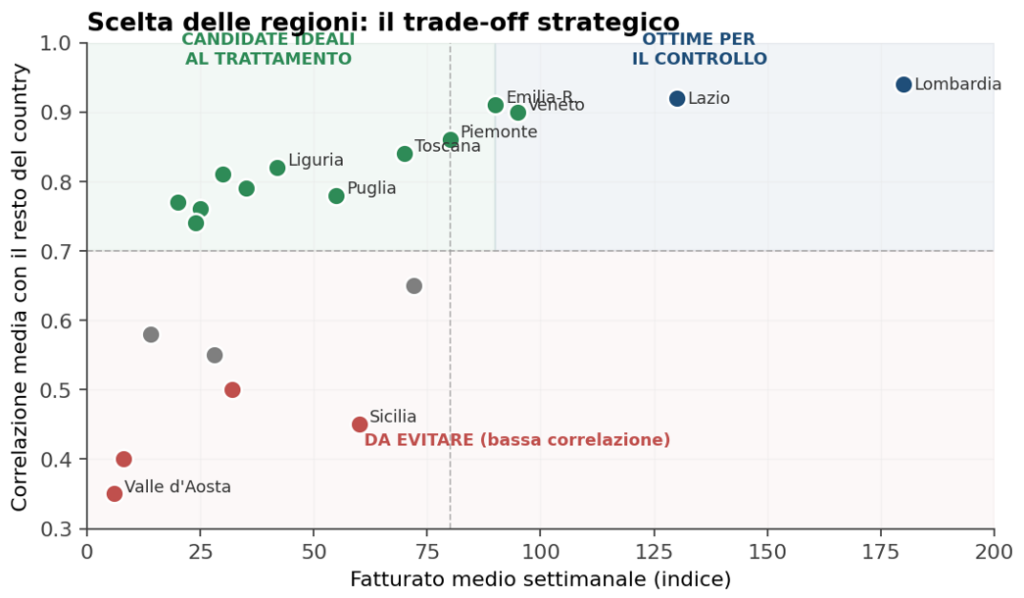
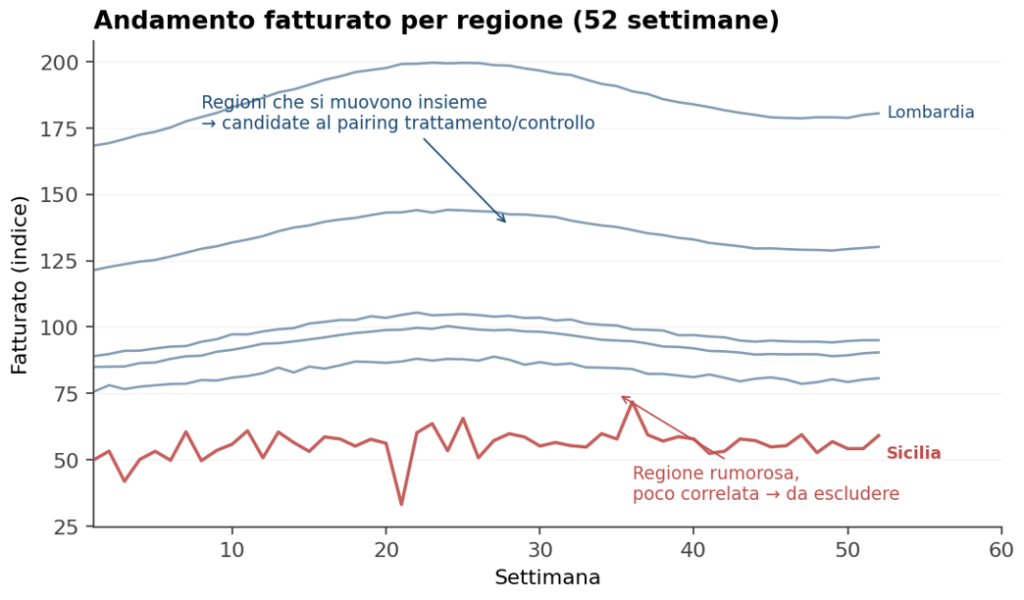
Figura 2 – A sinistra: l’andamento del fatturato per regione mostra immediatamente quali si muovono insieme (candidate al pairing trattamento/controllo) e quali sono troppo rumorose. A destra: incrociando correlazione e fatturato medio si individuano le regioni ideali per il trattamento (alta correlazione, fatturato moderato) e quelle ottimali come controllo strategico.
Durata, budget, errore: i tre vincoli da bilanciare
Le candidate ideali al trattamento sono dunque regioni con alta correlazione e fatturato moderato: abbastanza grandi da produrre segnale, abbastanza piccole da contenere il costo del test. Le regioni grandi (Lombardia, Lazio) sono spesso più preziose come gruppo di controllo – il loro storico è ricco e correlato, e non rinunciamo al loro fatturato durante il test.
Una volta selezionate le regioni, restano da definire tre parametri legati tra loro da una formula precisa: a parità di tutto il resto, il MDE (Minimum Detectable Effect – il lift minimo che il test sarà in grado di rilevare come statisticamente significativo) scende all’aumentare del budget incrementale e della durata, ma con rendimenti decrescenti.
In pratica, questo significa:
- Se voglio rilevare un lift piccolo (es. ≤3%), mi serve molto budget incrementale o molta durata, o entrambi.
- Se ho un budget limitato, posso ancora ottenere risultati validi allungando il test — pagando però in tempo decisionale.
- Se ho fretta (test di 4 settimane), devo accettare MDE più alti e quindi essere disposto a misurare solo lift importanti.
Il punto chiave è che il GeoLift permette di moltiplicare il budget locale sulle regioni trattate (raddoppiarlo o triplicarlo è frequente), ma se le regioni sono piccole il valore assoluto resta contenuto. È qui che la scelta delle regioni del paragrafo precedente si lega al test design: regioni troppo piccole limitano il budget incrementale assoluto e quindi peggiorano il MDE.
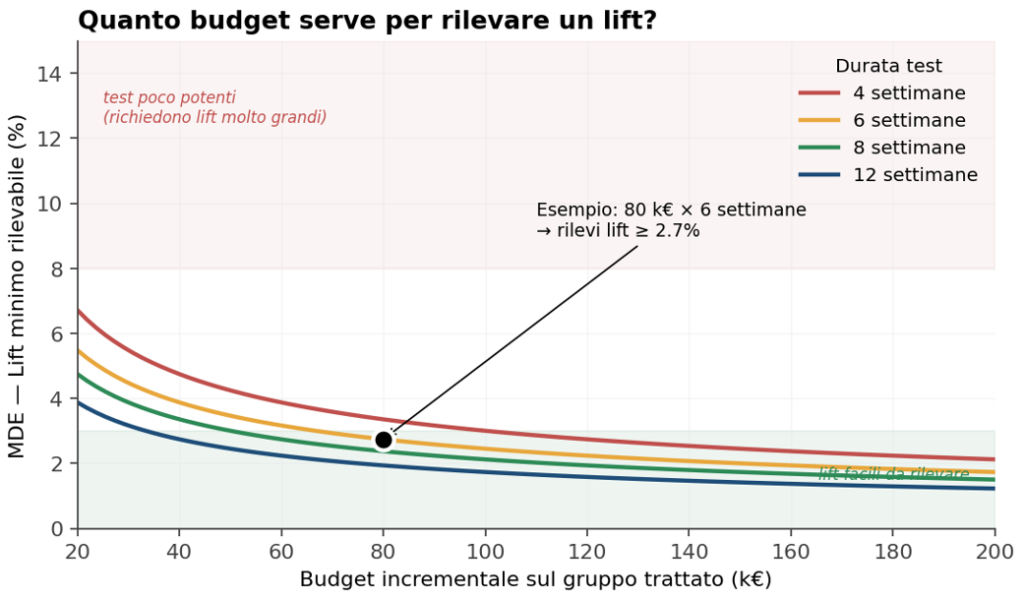
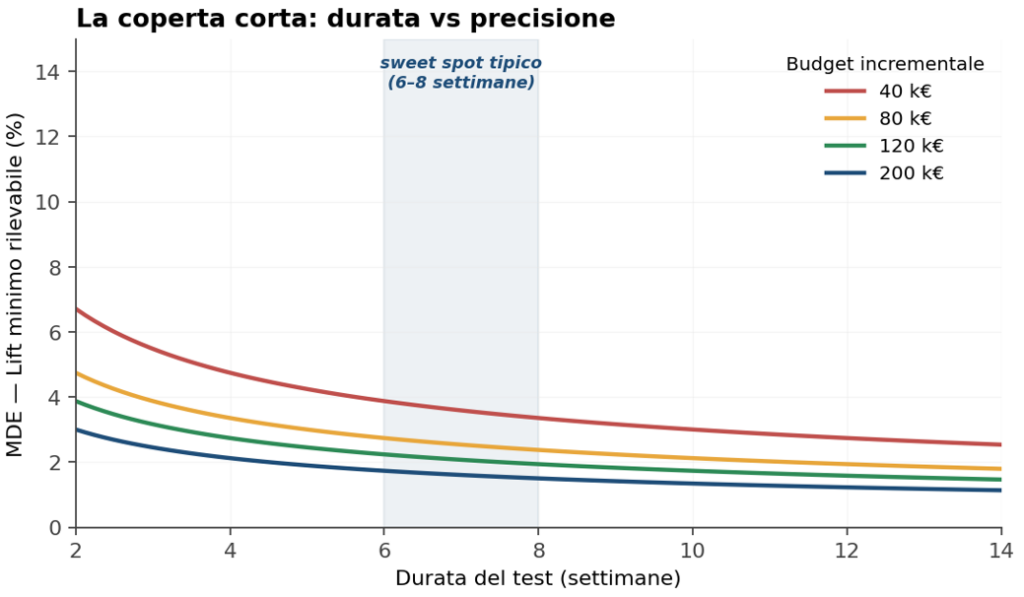
Figura 3 — La “coperta corta” del test design. A sinistra: a parità di durata, il MDE (lift minimo rilevabile) scende all’aumentare del budget incrementale, ma con rendimenti decrescenti. A destra: a parità di budget, allungare il test riduce ulteriormente il MDE. La banda 6–8 settimane è il compromesso più frequente tra potenza statistica e velocità decisionale.
La pratica matura suggerisce un sweet spot tipico di 6-8 settimane, con budget incrementale calibrato per ottenere un MDE compreso tra il 3% e il 6%. Sotto le 4 settimane si fatica a rilevare effetti realistici; oltre le 10-12 settimane il test diventa difficile da difendere internamente perché lega risorse troppo a lungo.
Quando il business chiede “ma serve davvero così tanto budget per così tanto tempo?”, la risposta non è negoziale ma matematica: si possono spostare i parametri lungo le curve, ma non si possono ridurre tutti e tre contemporaneamente. La coperta è corta.
Cosa cambia, concretamente, per chi addotta questo approccio
Le aziende che integrano GeoLift e MMM in un loop continuo osservano tre cambiamenti tangibili nel tempo.
Primo: gli intervalli di confidenza si stringono. Ogni GeoLift integrato come prior riduce l’incertezza posteriore sui coefficienti del modello. Dopo due-tre cicli, le stime di ROAS sono significativamente più precise di quelle di un modello standalone.
Secondo: la fiducia interna cresce. Quando il CFO chiede “siete sicuri di questo numero?”, la risposta non è più “il modello dice così”, ma “il modello dice così, e l’abbiamo validato causalmente nel Q2”. È una conversazione completamente diversa.
Terzo: il marketing diventa più audace. Decisioni di riallocazione del 15-20% del budget — che con un modello fermo richiederebbero mesi di discussione interna — diventano sostenibili, perché poggiano su evidenza causale recente.
Da dove iniziare
Se hai già un MMM in produzione, il primo passo non è rifarlo: è identificare il primo punto di calibrazione. Quale canale, quale decisione, quale incertezza meriterebbe per primo un test causale? Tipicamente è il canale dove il dibattito interno è più acceso, o dove una riallocazione potenziale è più impattante.
Se invece stai progettando il tuo measurement stack da zero in chiave post-cookieless, il MMM resta il punto di partenza naturale. Il GeoLift entra dal secondo trimestre, nel ritmo regolare del ciclo – non come progetto straordinario, ma come pratica continua.
Il risultato finale, dopo un anno di loop, è un sistema di measurement che pochi competitor avranno: un MMM che non è solo solido, ma che diventa più solido ogni trimestre.
In AD Cube progettiamo MMM bayesiani e ne curiamo la calibrazione continua attraverso GeoLift e altri esperimenti causali. Se vuoi capire come trasformare il tuo measurement in un sistema di apprendimento continuo, parliamone.
Author
AD cube